



Hello there. If I use averaging collection mode and set it to 2 minutes, if same of the collected values are way off, are they going to ruin the average value or the system is smart enough to ignore them?
1 Like
That’s an excellent question @kostismagalios ! Sometimes I’ve have asked myself that very question. Perhaps this is a source of bad positioning that some users have reported. I always let the receivers settle down a bit (maybe 1 minute) to get a good fix then start averaging.
I don’t use my Emlids much like I used to as I’m mainly an office surveyor, however when I get to a least start a project or even a simple one, I always take my Emlids and my Javad rover. In Javad’s methodology, you only collect data based on certain pdop, accuracy and of course time. You can set the software to re-verify the position by re-observe the same dataset and it compares the accuracy to the first position. Of course there are other myriad ways to do this but it’s the quickest. You also can set the 6 engines in the receiver to each get a position and compare also. However this is long process about 5 minutes and is only used for precise position for property corners.
Emlid needs to have some kind of option to at least re-verify the previous position or at least a “distance” to last computed point. Even this simple use would give the user some kind of confidence in the point observed. I’ve mentioned this before but it appears to fall on deaf ears.
4 Likes
Emlid has recently implemented steps to better ensure quality.
Firstly, they add the ability to set a Precision Limit when collecting points. Now you can specify minimum residual values in addition to Fix. I have tested this, and it works. If the value is exceeded during an average, the point collection will fail and start again.

Regarding the verification of the point by re-averaging, you could do that in Flow.
- After you collect the point, you could then immediately Stakeout the point without moving the receiver. It should tell you how far off it thinks the point is.
But that would not compare an average to an average. You can compare two averaged points with the Inverse tool in the Survey tier of Flow.
- Collect the point two times; e.g. point 1a and Point 1b. Then, open the Inverse tool and select the 2 points. Flow will show you the difference between the 2 points.

1 Like
Are you talking about single/float or fixed averaging? If you are talking about RTK-fixed you shouldn’t have any outliers unless the corrections drop, by which there is a setting to only accept fixed values. For an average-single point you get what you get. The point is that you get a point whether it is accurate or not so that you can converge and get a fix on another device to achieve relative accuracy. You should let the receiver baked for a good 15 minutes before starting your average and then let it average for a good 10-15 minutes. This is the only way you will get enough good samples to override the outliers.
2 Likes
This is great for high-precision fixed work but that’s about it. Anything outside of that will just get in a never-ending loop because even a float will often bounce way past an acceptable tolerance.
2 Likes
Thank you all for your answers but nobody answered to my question. (Not that somebody outside of Emlid could answer)
As far as the optimal time of averaging I found recently a paper stating that 2 minutes is the optimal time. After that the improvement in precision is non existent
2 Likes
It’s hard to answer a question so vague. As I asked before, what kind of average are you talking about? A 2-minute fixed-average is typical. It is different for the other positioning accuracy levels.
4 Likes
Is this question vague? I am talking about everything above 1.5cm that is the theoretical precision.
Let’s say that i get 1, 1.1, 0.9, 1, 1.2 and suddenly a wild 10 appears due to trees or buildings
1 Like
Not vague, it’s a good question but there is a lot more going on under the hood to also consider & potentially do yourself.
A receiver can’t see the buildings and tree so difficult for it to determine what’s good and what’s multipath and bad to reject. Receivers like the Trimble R12i do have incredibly powerful & proprietary software algorithm’s (ProPoint) that can sense & eliminate most multipath effects e.g. in heavy vegetation but these benefits come a $20k cost.
Otherwise, most receivers provide time proven simple averaging. The idea being that over time with enough data the impact of the outliers will reduce and not significantly affect the statistical result. They will not “ruin” the result. And over time the physical aspects also tend to net out, as the satellites move the multipath varies. E.g. the objects that reflect change, as do the angles and distances to the receiver. Time is your best friend.
As an example of this, the requirements to calibrate a survey mark in my state of Australia are a minimum static observation of 1 hour with 5 seconds logging, or two (independent) continuous static observations of 5 minutes each in metro (10 mins regional) with 1 second logging, and at least one hour apart.
If you are interested in real cm RTK accuracy (e.g. not just face value false fixes and other distortions), then 2 minutes is way too short. If you are happy to be within a handful of cm and are pressed for time it’s your own value judgement. Personally, for anything of relative interest I collect an absolute minimum of 3 minutes, and upwards from there to 30mins or more for something legally or dimensionally important.
To give you some idea why, you can see the typical GNSS convergence curve in the results of my own testing of precise geodetic equipment over a relatively long’ish 13.8km baseline and post-processed through Emlid Studio here: More functions and better usability request for Emlid Studio - #15 by Wombo
Only Emlid can answer if they apply any additional processing algorithm’s to the RTK averaging, but I wouldn’t expect a lot of detail as anything they did would be commercially sensitive.
Otherwise, your own practices would have a far more significant effect on reducing the impact of outliers in difficult environments. The time proven ones are:
- Time, as long an observation / average as you possibly can.
- If it’s really important then drop the RTK and do static.
- An onsite base, minimal baseline in the same environment.
- Reference marks to validate your results & re-observe as needed.
I understand your original question is in relation to the software algorithms but if you are not doing point number 4 then that question and the outliers becomes somewhat moot.
4 Likes
I really like how the JAVAD receivers calculate the location with the parallel RTK engines.
3 Likes
Hi @kostismagalios,
Averaging the point should give you more data to use for computing your survey data, so we suggest averaging the receiver for a certain time. We can’t give one specific time because this will depend more on the environmental conditions, clear view, and no obstructions.
As the comments from other users here in the thread suggest, the average time could vary due to environmental conditions or workflow. We suggest collecting the points for at least 30 seconds of observation, so in your case, 2 minutes is good. This would help the receiver calculate its position with more data.
If you need absolute accuracy, you can obtain the precise position of the base by uploading your RINEX observation file in OPUS (if you are in the US) or using a PPP service like NRCAN 1.
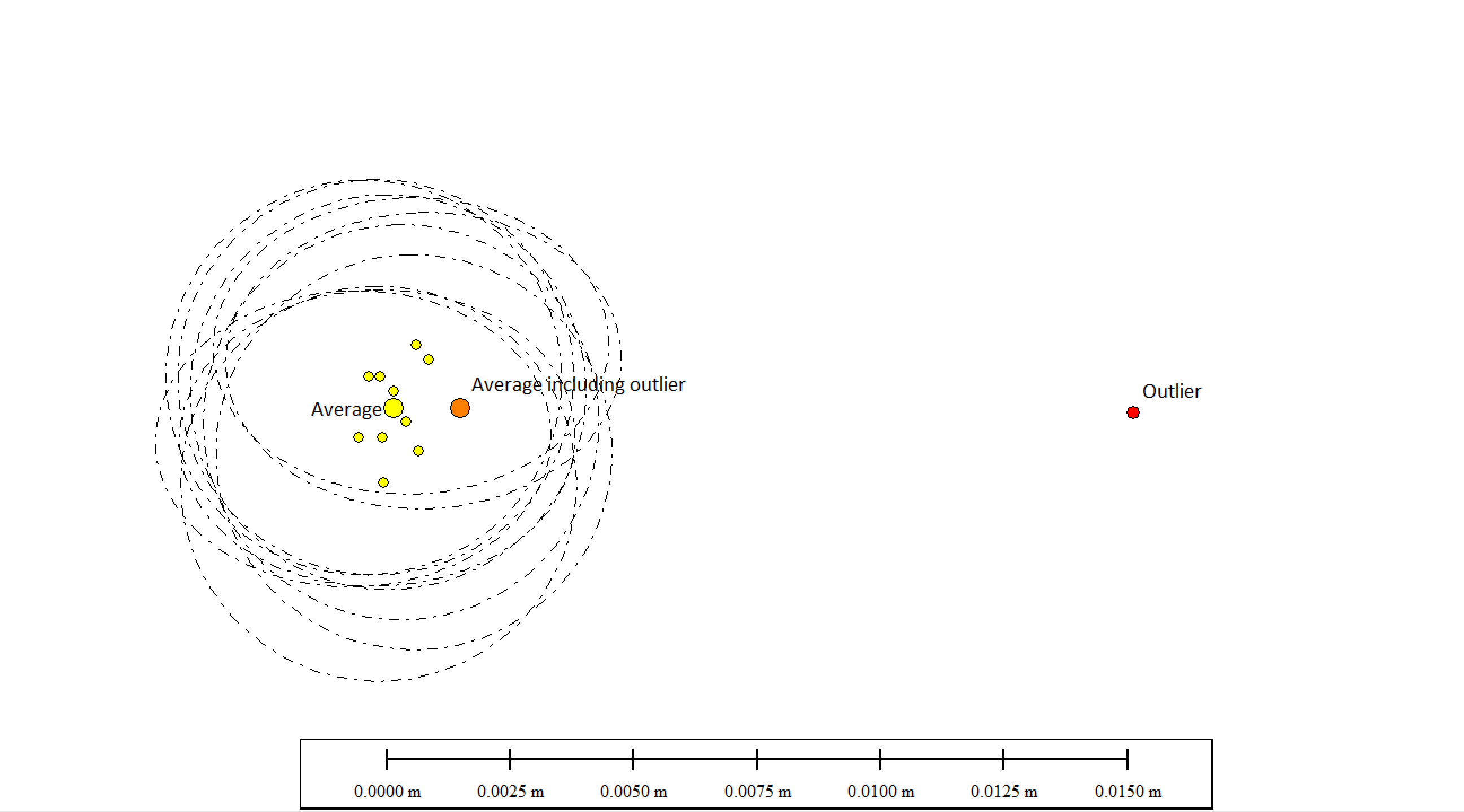
Here’s a visual illustration that may help. This plot shows 10 real positions I’ve collected to recalibrate my base with our updated AUSPOS V3. I’ve also plotted their 95% positional uncertainty ellipses (3-4mm), along with the computed average of all the positions.
For hell of it I then manually entered a rogue outlier position 10 times further out and reprocessed the average.
You can see quite clearly the impact is minimal, the new average still falls well within the original combined uncertainty ellipses and so is quite acceptable.
In this case it’s all at the mm level obtained with Geodetic equipment over multiple day observations, but the same math’s applies at the cm level with Emlid & RTK.
Simple averaging is good, that’s why we do it. Nothing is ruined.
And the subliminal message here is also reinforcing what is possible with your best friend, sufficient time. In this case all of the 10 real positions fall within 2.9mm.
3 Likes
This topic was automatically closed 100 days after the last reply. New replies are no longer allowed.