Hi All,
I am having trouble with OPUS solution. I have read the other Emlid threads and can’t seem to come to a working solution. I am using a 7 hour log from an M2. 30 sec intervals, GPS only, RINEX 3.03 (OPUS setting in Reach). My only thoughts are that either I’m not waiting long enough for OPUS to update, or the M2 is not capable of producing a working file (I believe it has limited percentage of satellites). I’m just not sure. I’ve attached the file here. Thank you for any help, it is much appreciated.
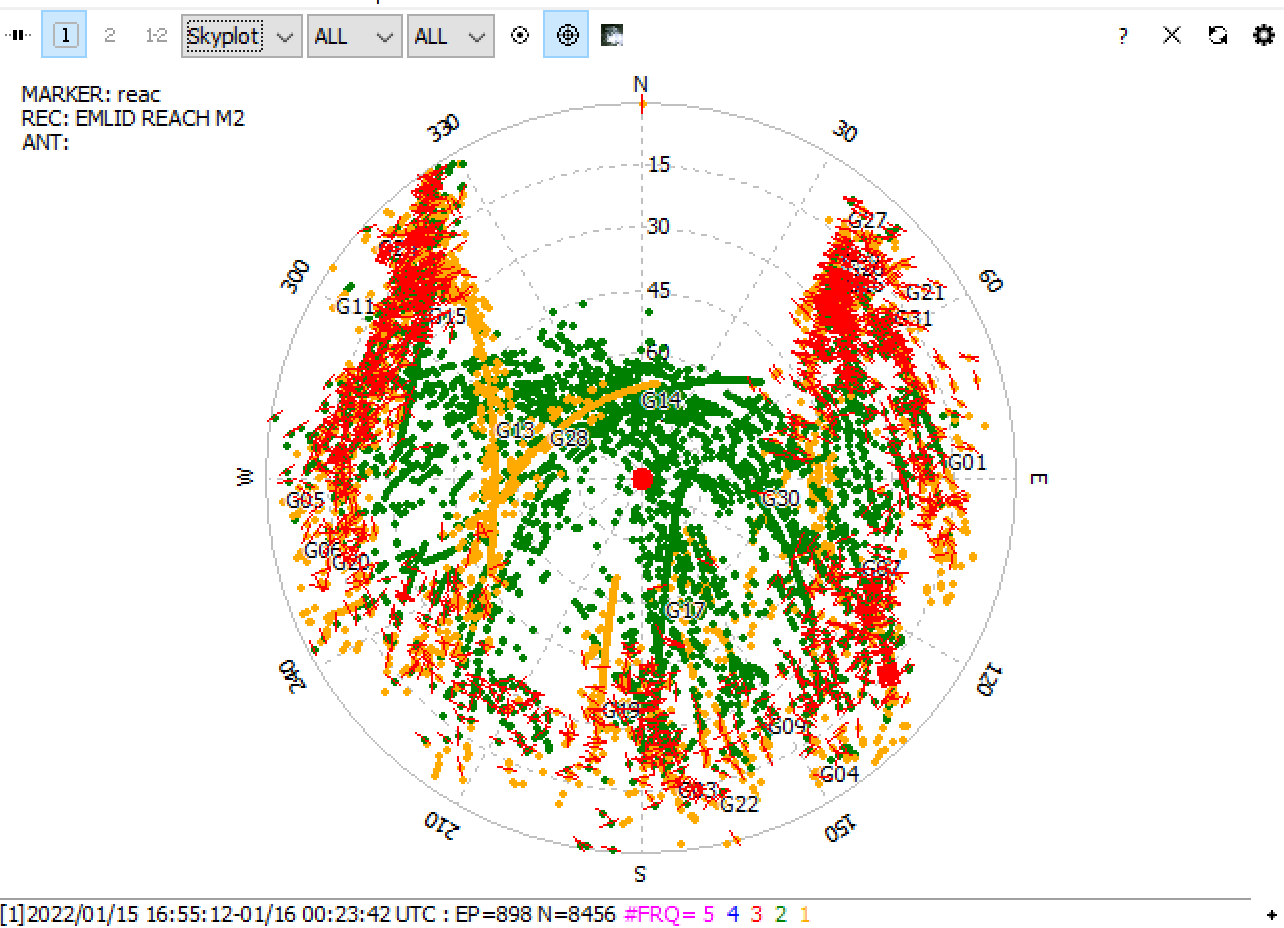
EDIT: I don’t have good clear sky view due to trees. Is it possible I’m just not getting good signal? Ty.
2m pole, with tripod. The environment isn’t very good. Tall trees and buildings are close by, so it’s difficult to retain fix in this area (I’m actively looking for an environment I can run my equipment that is secure). The other issue is there is a hot tub and perhaps it has electric interference?
It was processed well. However, as I see, only 57% of the observations were used in calculations. The rest were rejected.
I’d explain it by poor logs quality. As Christian mentioned, there are too many cycle slips in the OBS file, so the environmental conditions weren’t good enough indeed.
Hi. We’ve tried a new location which showed excellent reception to satellites. I let the unit run for about 4 hours. The unit was switched off at approximately 7:30pm PST last night Jan 19th. I’ve tried running through OPUS again but I still get a failure message. Should I wait longer? Thank you for any input. Here is the link to the Base log files…
Edit: we use antenna HXCGPS500 with an M2 unit
Edit 2: One thing occurred to us that this particular session ended past the 00:00 hour for UTM and perhaps we need to wait the extra 24 hrs to get a good read on the file from OPUS. Just a thought.
Yep, OPUS bombs with several different iterations of the data. Maybe waiting until at least the rapid orbits are available will help?
The good news is NRCAN PPP processes the data well (using their ultra rapid orbits) and a similar solution can be obtained in RTKLIB with differential processing of data from the nearby P224 CORS station.
The NAD83(2010.0) coordinates I get from both are:
37 50 01.217; -122 13 02.239; 149.09 meters HAE
Hi Julia,
That is a tremendous help. Please let us know if we can provide you with anything to help you. I really appreciate your attention to our problem.
We’ve been in contact with OPUS during all this period. Julia is out of the office now, so I’ve continued the investigation. Sorry it took so long to write back!
OPUS support says there were cases when one log was processed well for data collected in similar conditions, and another one was aborted. There’s no apparent reason for that. Sometimes, cutting off a few minutes at the beginning of the log can help. I’ve tried it out, but it didn’t work for your data.
Then, I’ve uploaded your log to PPP services (NRCAN and AUSPOS). Everything worked as intended, and I got accurate coordinates from both. That’s why I think the issue was indeed related to internal OPUS processes.
Looks like it’s a rare case. But if you face it again, I’d recommend trying out PPP.
Thank you so much, I really appreciate the attention to our issue! I ended up moving the base into a place with less trees and the OPUS solution began to be accepted. I think I will try what you suggest with the old logs and different services and see if I can recover anything.